Active Stereo Without Pattern Projector
ICCV 2023
|
|
|
|
|
|
|
|
Journal Extension CVPR24 Demo ECCV24 Demo

|
|
Virtual Pattern Projection for deep stereo. Either in challenging outdoor (top) or indoor (bottom) environments (a), a stereo network such as PSMNet often struggles (b). By projecting a virtual pattern on images (c), the very same network dramatically improves its accuracy (d). By further training the model to deal with the augmented images (e) further improves the results. |
Abstract
|
"This paper proposes a novel framework integrating the principles of active stereo in standard passive cameras, yet in the absence of a physical pattern projector. Our methodology virtually projects a pattern over left and right images, according to sparse measurements obtained from a depth sensor. Any of such devices can be seamlessly plugged into our framework, allowing for the deployment of a virtual active stereo setup in any possible environments overcoming the limitation of physical patterns, such as limited working range. Exhaustive experiments on indoor/outdoor datasets, featuring both long and close-range, support the seamless effectiveness of our approach, boosting the accuracy of both stereo algorithms and deep networks." |
Method
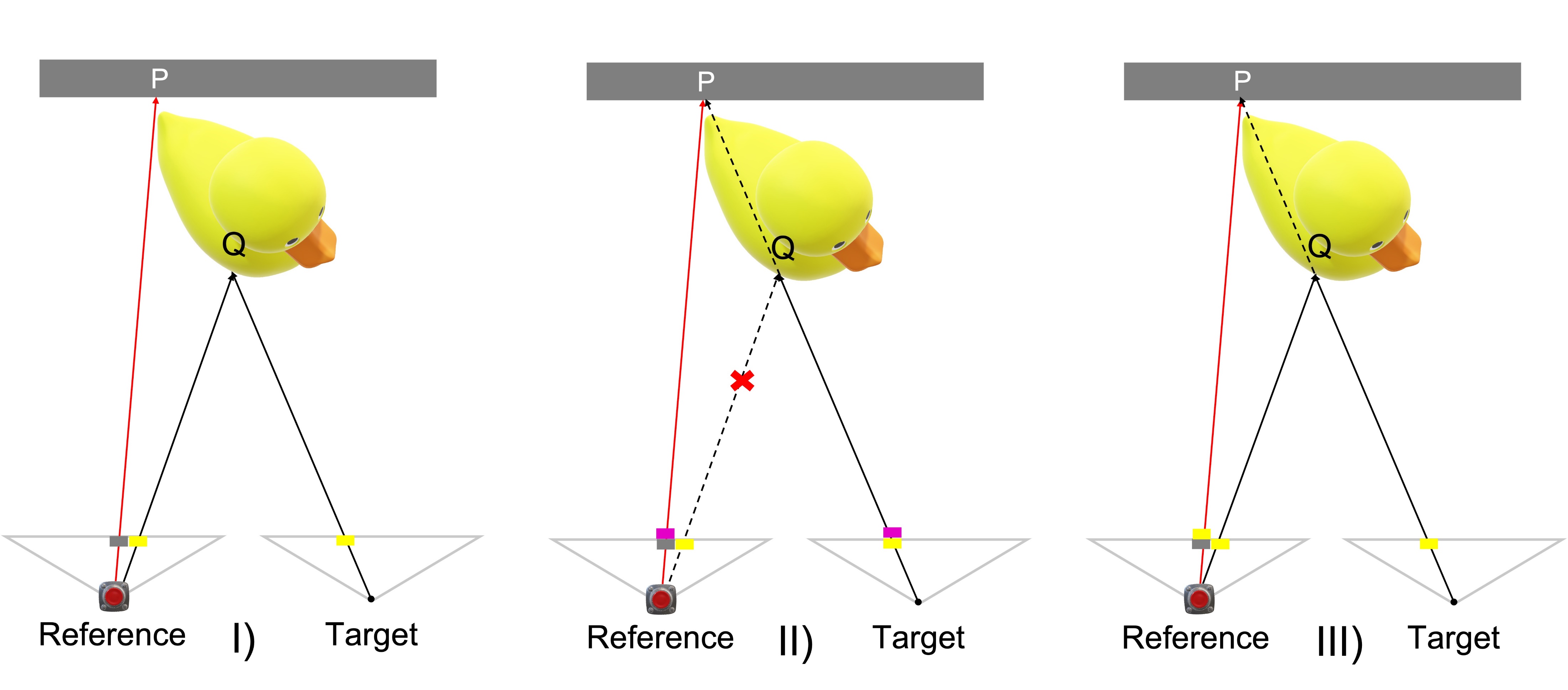
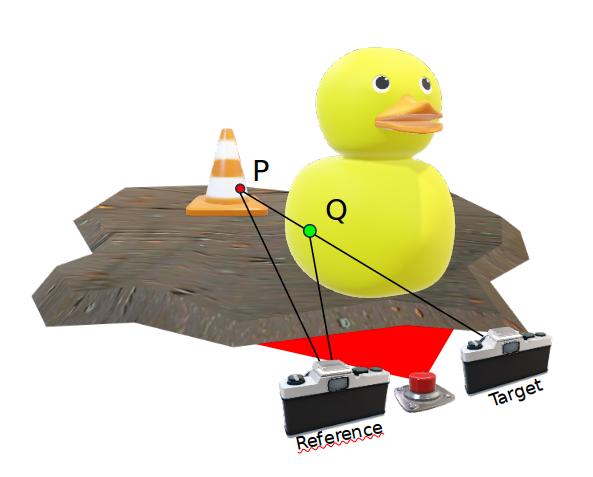
1 - Problems
|
|||||||||||||||||
2 - Proposal
|
|||||||||||||||||
3 - Virtual Pattern Projection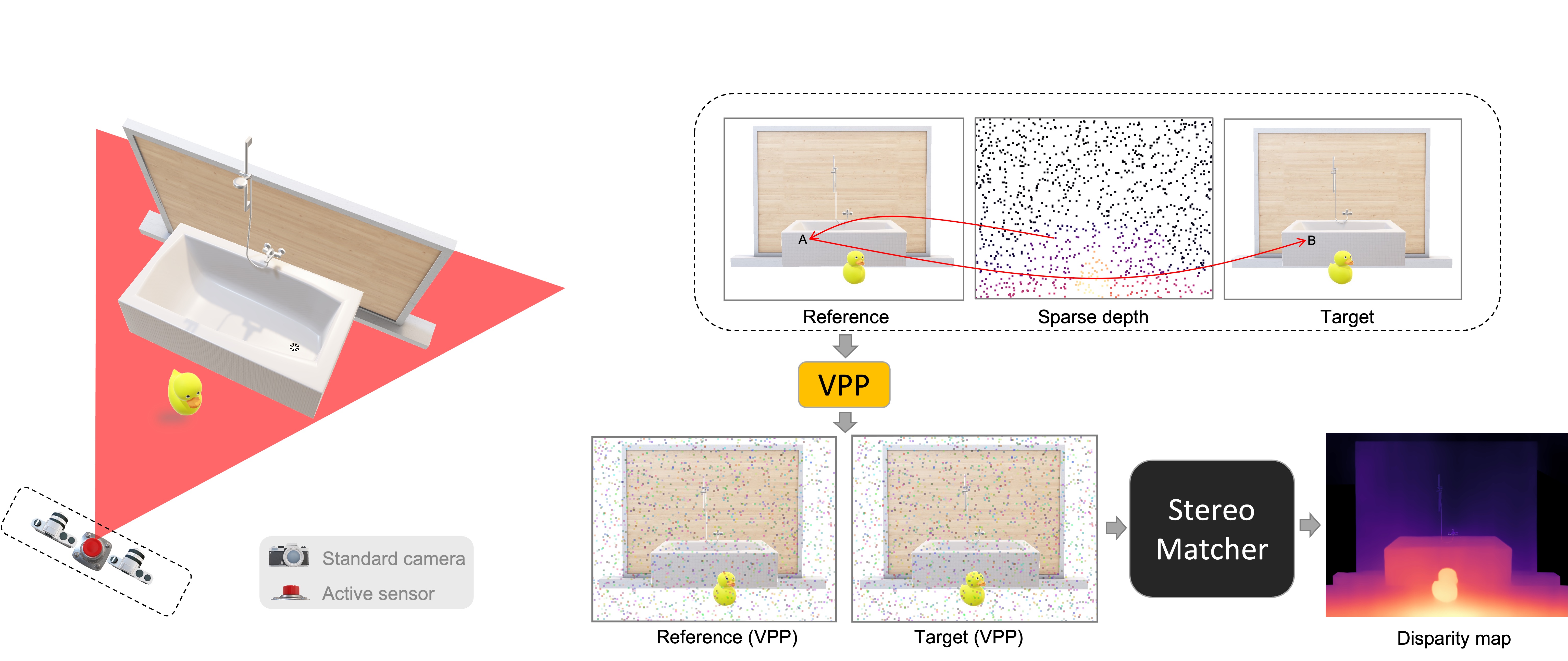
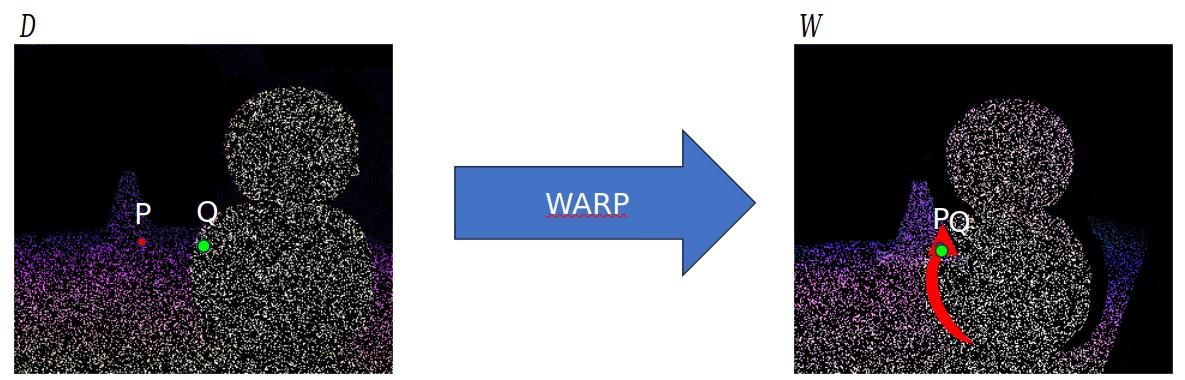
As for all fusion methods, our proposal relies on sparse depth seeds but, differentially from them, we inject sparse points directly into images using a virtual pattern. For each known point, we convert depth into disparity then we apply a virtual pattern in each stereo image accordingly to a pattering strategy. $$I_L(x,y) \leftarrow \mathcal{A}(x,x',y)$$ $$I_R(x',y) \leftarrow \mathcal{A}(x,x',y)$$Our method do not require any change or assumption in the stereo matcher: we assume it to be a black-box model that requires in input a pair of rectified stereo images and produce a disparity map. Augmented stereo pair is less affected by ambiguous regions and makes stereo matcher work easier. Given that our framework alters only stereo pair, any stereo matcher could benefit from it. Since disparity seed could have subpixel accuracy, we use weighted splatting to avoid loss of information. $$I_R(\lfloor x'\rfloor,y) \leftarrow \beta I_R(\lfloor x'\rfloor,y) + (1-\beta) \mathcal{A}(x,x',y)$$ $$I_R(\lceil x'\rceil,y) \leftarrow (1-\beta) I_R(\lceil x'\rceil,y) + \beta \mathcal{A}(x,x',y)$$ $$\beta = x'-\lfloor x'\rfloor$$We propose different pattering strategies to enhance distinctiveness and high correspondence, a patch-based approach to increase pattern visibility, alpha-blending with original content to deal with adversial issues with neural networks, a solution to ambiguous projection on occluded points and consequentially an heuristic to classify occluded sparse points. In particular:
|









Video
|
|
Experimental Results
Performance versus Competitors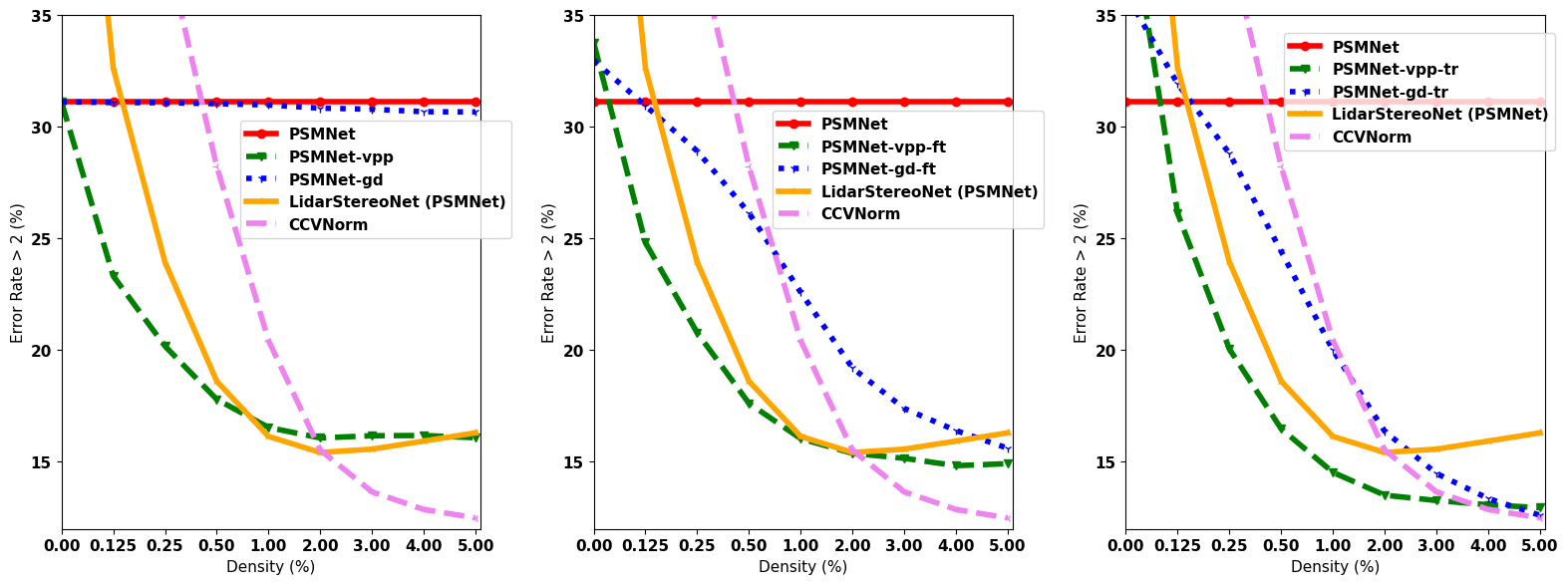
Plots show the error rate on Middlebury 2014 training split, varying density of sparse hint points from 0% to 5%. We compare two stereo networks together with our VPP framework against:
As shown in the figures, VPP generally reaches almost optimal performance with only 1% depth density. Except few cases in the training configurations with some higher density, VPP achieves much lower error rates. |
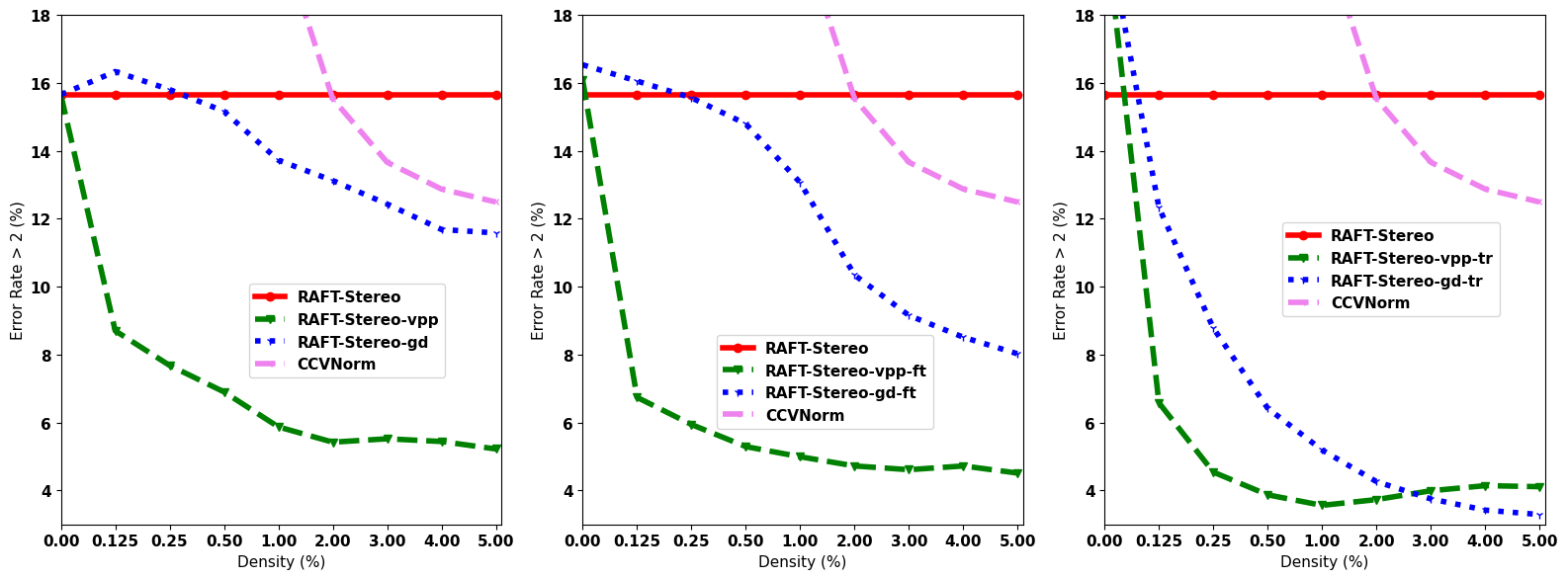
VPP with off-the-shelf networks
These last plots show the effectiveness of our technique using off-the-shelf networks (i.e., HSMNet, CFNet, CREStereo, RAFT-Stereo) on four different datasets:
Even without any additional training, our framework boosts accuracy of any model with rare exceptions. |
BibTeX
@InProceedings{Bartolomei_2023_ICCV,
author = {Bartolomei, Luca and Poggi, Matteo and Tosi, Fabio and Conti, Andrea and Mattoccia, Stefano},
title = {Active Stereo Without Pattern Projector},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {18470-18482}
}